當我們在感嘆ChatGPT的妙語連珠時,你是否好奇過:究竟是什么樣的“心臟”,在支撐這些超級AI沒日沒夜地思考?答案不是你熟悉的CPU,也不僅僅是顯卡GPU,而是一位更專注、更硬核的“特種兵”——TPU(Tensor Processing Unit)。
今天,作為國產可重構TPU芯片的先行者,萬協通將帶你剝開晦澀的技術外殼,看懂這塊決定AI未來的核心硬件,以及中國芯片如何換道超車,上演一場精彩的“變形記”。
AI時代的“偏科生”——讀懂TPU
在芯片的大家族里,如果說CPU是總指揮官:擅長規劃,不擅長搬磚;GPU是施工大隊:能承接各類任務卻受限于固定作業流程;那么TPU就是特種機甲:專用、適合、極速。
1. 為什么AI不愛用CPU?
CPU內部擁有極其復雜的控制單元(Control Unit),擅長邏輯調度和統籌規劃,但負責具體計算的ALU(算術邏輯單元)占比并不高。它就像一位“統領全局的總指揮官”,運籌帷幄決勝千里,但如果讓他親自去處理AI模型里成千上萬個繁瑣的加減乘除,效率極低。
2. GPU不僅僅是用來打游戲的
GPU雖然堆疊了成千上萬個SM(流式多核處理器)單元,就像一支“全能的裝修大隊”,人多力量大,什么活都能干。但它依然受限于傳統的馮諾依曼架構,SM單元需要頻繁訪問內存,如果沒有大內存支撐,經常會因為內存帶寬不足(“缺料”)而停工等待。
3. TPU:為AI而生的“數學天才”
萬協通可重構TPU芯片采用了創新的可重復應用的BOU(基本運算單元)架構。這些BOU就像是可靈活組裝的特種裝備,專門針對AI張量運算進行了極致優化。它不再是通用的工具,而是“為AI量身定制的特種機甲”。通過BOU的靈活重構,應對各種數據的運算時暢通無阻,實現了極致的專用性與速度。一句話總結,可重構TPU芯片專精于一件事:矩陣運算。
撞上“內存墻”——傳統架構的困境
傳統的芯片架構(馮·諾依曼架構)發展至今仍保留著一個致命傷:“計算”和“存儲”是分家的。
想象一下,一位頂級大廚在炒菜,但他的冰箱卻在三公里外。
每炒一道菜,大廚都得停下來,開車去冰箱拿一顆蔥;
切完了,再開車去放回刀;
炒完了,再開車把盤子運回冰箱。
這就是芯片界著名的內存墻問題。在傳統AI芯片中,90%的功耗和時間其實都浪費在了“運送數據”的路上,而不是真正的“計算”上。 這導致了高昂的電費、巨大的發熱量和難以降低的成本。
萬協通的破局——做芯片界的“樂高大師”
面對這一行業痛點,萬協通沒有選擇盲目堆砌硬件,而是秉持著高效利用,持續優化的理念,提出了一套革命性的解決方案。
萬協通的思路很簡單:既然數據在內存與計算單元間反復搬運太慢,那我們就重構數據通路,讓數據在計算單元間直接“接力”流轉,不再反復進出內存,徹底打破“內存墻”的阻隔。

圖1:不同芯片架構特性與定位對比
萬協通自研了獨有的可重構TPU架構。在他們的芯片里,不再是靜態的電路,而是由無數個基本運算單元(BOU,Basic Operation Unit) 組成的動態可配置電路。
這些BOU就像是樂高積木:
當AI模型需要做“卷積”運算時,軟件一聲令下,積木瞬間拼成“卷積機”;
下一秒需要做“全連接”運算時,它們自動拆散,重構成“乘法器”。
這種“軟件定義硬件”的能力,讓芯片具有了生命力。它不再是被動地跑程序,而是根據程序的需求,主動改變自己的物理結構,達成100%的算力利用率。
為了打破“內存墻”,萬協通設計了流水線(Pipeline)數據并行架構。
數據一旦進入芯片,就像上了流水線。上一級BOU算完,直接扔給下一級,中間絕不回寫到內存。消滅了無效的數據搬運,功耗大幅降低,計算效率成倍提升。
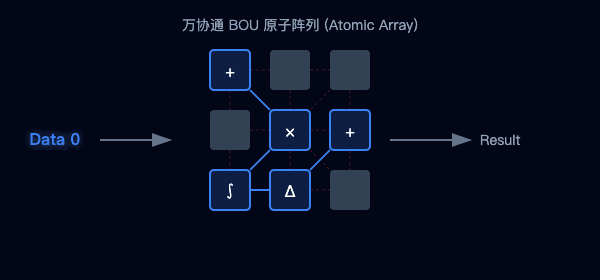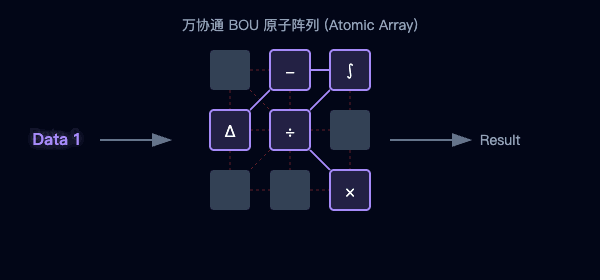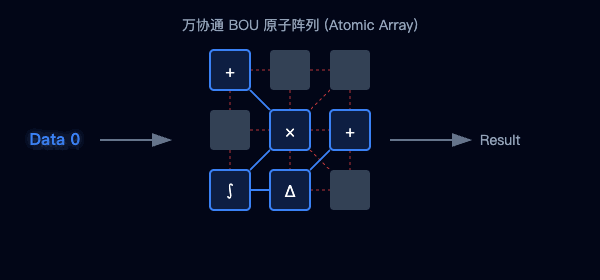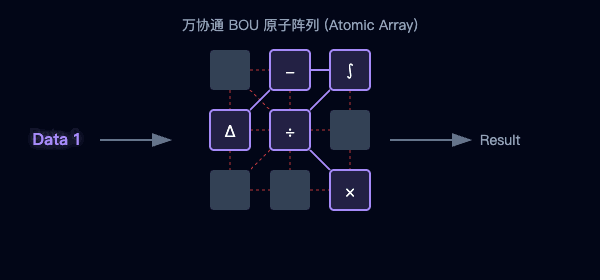
圖2:傳統架構的數據往返(左)與萬協通的并行流水線(右)對比
如果你關注國產芯片,一定聽說過“CUDA生態壁壘”。很多國產芯片之所以難用,是因為不僅要造硬件,還要去適配成千上萬個復雜的軟件“算子”。
萬協通做了一件“釜底抽薪”的事。
他們發現,無論AI算法多么花哨,拆解到底層,都是線性多項式運算。
因此,萬協通的可重構TPU芯片不需要龐大的算子庫,當遇到新模型時,編譯器直接指揮BOU這些“原子”現場搭建。
這意味著:萬協通的芯片天生具有極強的適應性,無需漫長的軟件適配周期,拿來就能用。
【原子重構,萬象隨心】
萬協通并非單純的芯片制造者,而是底層計算架構的深度重構者。公司的核心技術特征在于對基礎運算單元(BOU)原子性與可塑性的極致挖掘。正是基于這一“底層重構”基因,萬協通打造了革命性的可重構TPU芯片——它能根據AI模型的需求,通過配置動態重組BOU這些“算力原子”,以流水線并行架構徹底打破傳統芯片的“內存墻”桎梏,實現了硬件架構對上層算法的完美適配與高效支撐。
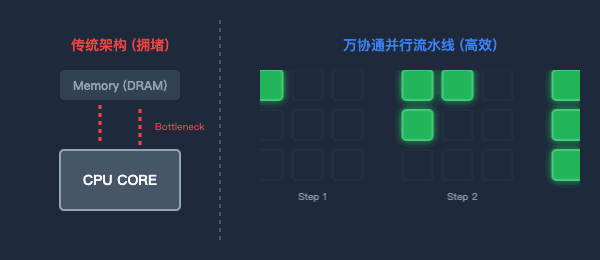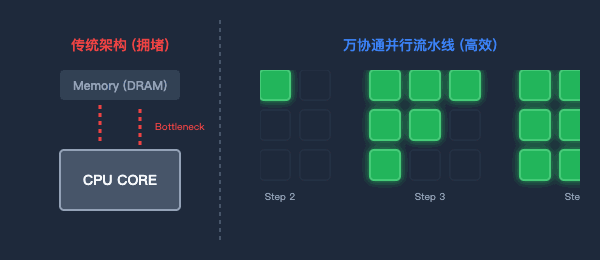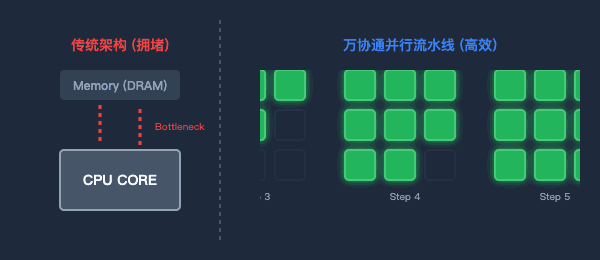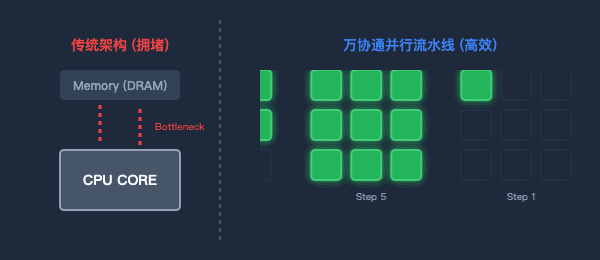
圖3:海量BOU原子陣列—聚沙成塔,按需重組
【降本增效的實干家】
在這個算力貴如油的時代,萬協通通過去掉昂貴的Cache(緩存)堆疊,利用可重構架構,實現了:
更小的芯片面積 = 更低的制造成本
更高的能效比 = 更省電的運行成本
這將讓高性能AI算力不再是巨頭的專利,讓更多的中小企業、邊緣計算設備也能擁有“超級大腦”。
在摩爾定律逐漸失效的今天,算力的提升不能再只靠死磕納米制程。萬協通的可重構TPU向世界證明:架構的創新,同樣能帶來指數級的性能飛躍。
作為國產可重構TPU芯片的先行者,萬協通不僅是在造一顆芯片,更是在探索一種讓硬件追隨軟件、讓算力像水一樣自由流動的全新范式。在這場關乎國運的算力競賽中,萬協通正帶著中國芯的智慧,突圍而出,重構未來。
免責聲明:市場有風險,選擇需謹慎!此文僅供參考,不作買賣依據。

新能源車最新一年保值率榜單出爐:問界M9、極氪009、理想MEGA包攬前三,

作者:于淼責編:陳娟一審:陳娟二審:孟姣燕三審:李偉鋒來源:湖南日

領克首款旅行車官宣2026年三季度上市拓局旅行車市場,領克,新車,上市,旅

記者從多家航空公司了解到,結合當前運行保障能力與地區局勢,為滿足廣

近日,北京市首個5G+醫療試點正式落地平谷。依托5G高速網絡與智能診療

南方財富網概念庫股票工具數據整理,截至2026年3月6日,京東外賣上市公

六氟丙酮商品報價動態(2026-03-07)

2025年前三季度,全國最大油服商中海油服攬獲近348 5億元營收,凈利潤3

1月26日挖掘的甲醇分支是化工股最具彈性品種,3月2日老樊挖掘的有預期

本報訊天眼查App顯示,近日,君樂寶乳業(泉州)有限公司成立,法定代

3月5日,生意社ABS基準價為10016 67元 噸,與本月初(8926 67元 噸)相比

3月5日,生意社鋁基準價為23966 67元 噸,與本月初(23406 67元 噸)相比

大家一起制作元宵一起吃湯圓猜燈謎給環衛工人送上慰問品為新就業形態勞

天眼查App顯示,近日,大城縣森普保溫材料廠(個體工商戶)成立,法定

天眼查App顯示,近日,河北省啟佑達化工貿易有限公司成立,法定代表人

2月26日,廣汽本田2026款冠道正式上市。其中,240TURBOCVT舒享版一口價

每經AI快訊,周三(3月4日)歐市尾盤,德國10年期國債收益率跌0 2個基
每經AI快訊,恒生指數主連夜盤收漲1 60%,報25534點。恒生科技指數主連

3月2日,2026款小鵬X9正式上市。該車超級增程CLTC綜合續航里程至高1602

每經AI快訊,3月4日,匯隆新材(301057 SZ)公告稱,停牌期間,公司控股

三花智控:和追覓科技沒有股權關系或者業務合作,三花智控,追覓科技,股

CBA熱身賽:遼寧101-94北控哈維首秀15分里勒空砍29分,哈維,遼寧飛豹,北

對陣馬競替補出場,阿勞霍達成巴薩200場里程碑,馬競,巴薩,國王杯,阿勞

大盤連續兩根大陰線是不是很多的信仰又跌沒了?和訊投顧陳愛國分析,第

,證券時報網
Copyright @ 2001-2023 m.sjttj.com All Rights Reserved 商業時報網 版權所有 關于我們
網站信息內容, 均為相關單位具有著作權,未經書面授權,轉載注明出處
未經商業時報網書面授權,請勿建立鏡像,轉載請注明來源,違者依法必究